El problema de los chatbots genéricos en entornos empresariales críticos
No todos los chatbots de IA están diseñados para decisiones críticas de negocio. Descubre cómo evaluar soluciones de IA empresarial cuando la confianz
La mayoría de los chatbots de IA parecen convincentes. Pero eso no significa que sean fiables.
Haces una pregunta, recibes una respuesta al instante y sigues con tu trabajo.
Eso funciona cuando una aproximación es suficiente. El problema aparece cuando los empleados necesitan apoyarse en documentación interna exacta para tomar decisiones comerciales, operativas o de cumplimiento normativo.
Un delegado farmacéutico que se prepara para reunirse con un médico no puede basarse en una cifra aproximada de eficacia. Un asesor financiero no puede “intuir” un umbral a partir de una política interna. Un ingeniero de campo no puede improvisar una tolerancia operativa consultando un manual técnico.
La cuestión no es si los chatbots documentales son útiles. La cuestión es si su arquitectura de recuperación de información es lo suficientemente sólida para entornos donde la precisión no es negociable.
El problema de los chatbots que “parecen acertar”
La mayoría de los chatbots documentales siguen un patrón muy similar:
- recuperan contenido semánticamente similar
- lo procesan a través del pipeline de recuperación y generación
- producen una respuesta bien redactada
Esto mejora el acceso a la documentación, sí. Pero similitud semántica no equivale a evidencia exacta.
Y esa diferencia importa.
Un usuario pregunta:
"¿Cuál es el umbral aprobado bajo la condición B?"
La respuesta suena coherente. Parece correcta.
Pero… ¿ese valor exacto aparece realmente en la documentación indexada? ¿La condición es exactamente la misma? ¿Existe otro documento con una cifra distinta? ¿Y si la información estaba en un gráfico en lugar de texto?
Estas no son preguntas de interfaz. Son preguntas de arquitectura.
Fallo nº1: precisión numérica inventada
Las respuestas más peligrosas suelen ser las más convincentes.
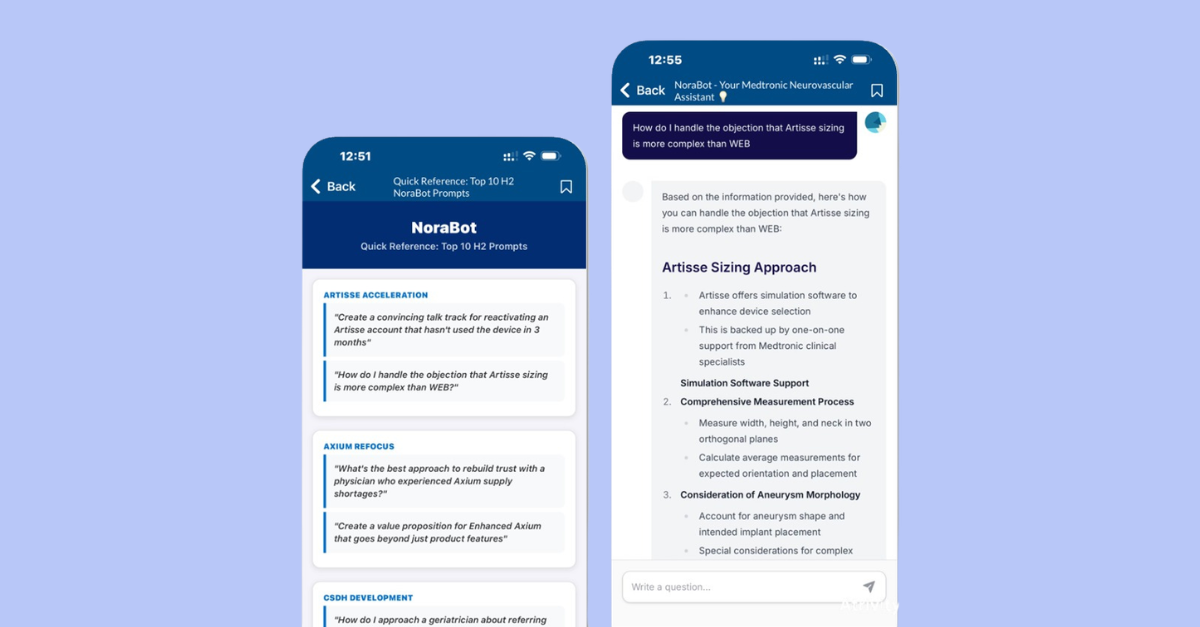
Imagina a alguien del equipo comercial de una farmacéutica buscando el resultado de un estudio antes de reunirse con un médico.
La documentación contiene múltiples porcentajes según endpoints, periodos temporales y perfiles de pacientes. Un chatbot genérico puede recuperar contenido relacionado y generar una respuesta impecablemente redactada.
La cifra parece creíble.
Eso no significa que sea defendible.
Un sistema empresarial realmente fiable debería seguir una regla mucho más estricta:
Cada valor numérico que muestra el sistema debe aparecer literalmente en la evidencia indexada.
Si no aparece, el sistema debería reconocer que no dispone de esa información, en lugar de inventarla.
No es una preferencia de experiencia de usuario.
Es un requisito de fiabilidad.
Fallo nº2: gráficos invisibles
La información crítica rara vez vive únicamente en párrafos.
También está en gráficos de rendimiento, tablas comparativas, diagramas técnicos, figuras de ingeniería o visualizaciones de producto.
Pensemos en un ingeniero industrial que pregunta:
"¿Cuál es la presión máxima para la configuración B?"
Si ese dato solo existe en un gráfico, un sistema basado únicamente en texto está incompleto por definición.
Muchos chatbots documentales dependen principalmente del texto extraído de PDFs. Eso significa que pueden “ver” el título o la leyenda… pero no necesariamente interpretar correctamente los valores reales del gráfico.
El usuario recibe una respuesta.
Pero no necesariamente la correcta.
Un enfoque más robusto funciona de otra manera:
Los gráficos y figuras se interpretan mediante IA multimodal y se contrastan con el texto original del documento.
Fallo nº3: contradicciones silenciosas
La documentación empresarial evoluciona constantemente.
Las políticas se actualizan. Las especificaciones cambian. Existen versiones regionales. Se publican revisiones.
La inconsistencia es inevitable.
Ahora imagina a un empleado del sector financiero preguntando:
"¿Cuál es el umbral mínimo de este producto?"
Dos documentos indexados contienen valores distintos.
Muchos chatbots simplemente devuelven el resultado con mayor similitud semántica.
La contradicción queda oculta.
Y eso es un riesgo.
Un sistema más fiable debería comportarse de otra forma:
Si dos documentos discrepan sobre el mismo dato bajo la misma condición, el sistema debe mostrar ambas fuentes en lugar de elegir una silenciosamente.
El trabajo del chatbot no es ocultar la ambigüedad.
Es hacerla visible.
Recuperar información no es suficiente
RAG se ha convertido en la arquitectura estándar para chatbots empresariales basados en conocimiento.
Eso ayuda.
Pero la implementación lo es todo.
Los sistemas más básicos tratan los documentos como texto libre.
Un pipeline más sólido extrae los datos como registros estructurados, incluyendo:
- sujeto
- valor
- unidad
- método
- condición
Porque el contexto define la precisión.
“12%” por sí solo no es conocimiento útil.
Una respuesta fiable necesita contexto y trazabilidad hacia su fuente.
Por eso, un enfoque robusto no trata los documentos como simples bloques de texto, sino como información estructurada y verificable.
Eso reduce ambigüedad y permite una recuperación exacta.
La velocidad importa, pero de poco sirve si la información está desactualizada
Los usuarios esperan respuestas rápidas.
Y repetir la misma consulta no debería obligar a ejecutar todo el proceso desde cero cada vez.
Un sistema con caché semántica puede devolver respuestas recurrentes en apenas unos segundos, invalidándolas automáticamente cuando cambia la documentación.
La velocidad importa.
Pero solo si la evidencia sigue siendo actual.
La oportunidad más interesante: visibilidad sobre las carencias de conocimiento
A veces, el dato más valioso no está en las respuestas correctas.
Está en las preguntas que no se pueden responder.
Las consultas sin respuesta revelan:
- documentación incompleta
- objeciones recurrentes del equipo comercial
- mensajes de producto poco claros
- incertidumbre técnica
- lagunas formativas que necesitan refuerzo
Eso cambia completamente el papel del chatbot.
Deja de ser una simple herramienta de soporte.
Y pasa a convertirse en una fuente de inteligencia operativa.
Para equipos de enablement, operaciones o IT, ese nivel de visibilidad puede ser incluso más valioso que el propio chatbot.
Qué deberían evaluar los responsables de decisión
Al valorar plataformas de chatbot empresarial, la interfaz no debería ser la pregunta principal.
Las preguntas realmente importantes son:
- ¿Cómo se validan los valores numéricos?
- ¿Puede el sistema interpretar gráficos y evidencia visual?
- ¿Cómo gestiona documentos contradictorios?
- ¿Cada respuesta es trazable hasta su fuente?
- ¿Cómo acelera respuestas recurrentes sin quedarse obsoleto?
- ¿Qué visibilidad ofrece sobre preguntas no resueltas?
Porque en sectores intensivos en documentación, el reto no es generar respuestas.
El reto es generar respuestas en las que tu equipo pueda confiar cuando la precisión importa.
Si tu organización está evaluando un chatbot empresarial fiable para documentación interna, Atrivity puede ayudarte a analizarlo.
¿Listo para cerrar la brecha entre formación y rendimiento?
Descubre cómo organizaciones de todo el mundo convierten el conocimiento en resultados medibles con Atrivity.
Pruébalo gratis.png)